何为滤波
滤波,这个词本身就很形象。就像滤网一样,让有用的东西通过,把没用的拦下来。但在信号处理里,事情没那么简单——你需要保留的是“目标信号”,过滤掉的是“干扰噪声”。
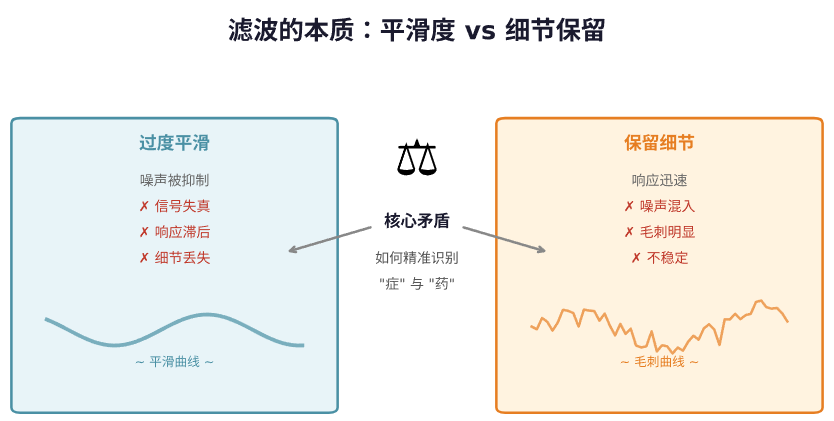
这里其实就藏着第一个核心矛盾:你怎么知道哪些是目标,哪些是干扰?如果目标信号本身也在快速变化,那它和噪声的“高频”特征看起来很像,你硬要去滤,很可能把重要的东西也一起抹掉了。
所以滤波的本质,就是在平滑度和细节保留之间做权衡。你追求平滑,就必然牺牲一部分响应速度;你想保留全部细节,噪声就会钻进来。所有滤波算法的差异,说到底,就是在这个权衡上各自站的位置不同。
而错误的滤波,会直接导致数据失真。这就引出另一个思考:既然不同的干扰需要“对症下药”,那么一个滤波器好不好,就看它能不能精准地识别出哪些是“症”,哪些是“药”。
平均滤波
平均滤波是最直觉的滤波方式。它的逻辑简单到不需要任何数学基础就能理解:既然噪声是随机的,时高时低,那我就多采几次,取个平均值,噪声不就被“平均掉”了吗?
这种想法非常朴素,也确实有效。从概率的角度说,如果噪声的均值为零,采样次数越多,平均值的方差就越小,也就是说,你会得到一条越来越平滑的曲线。
但问题也随之而来。你“平滑”的代价是时间——你要等很多次采样,才能给出一个值。这直接导致了系统响应变慢,也就是滞后。而更致命的是,在等待的这段时间窗口里,真实信号其实也在变化,你却把它当成一个恒定值去平均了。结果就是,你不仅滞后了,还把信号的真实变化给“压扁”了。
为了改进,后来有了加权平均。它的想法同样直觉:凭什么窗口里的每个数据都同等重要?最新采到的数据显然更能代表当前的真实状态,应该给它更高的权重。这可以看作一种“遗忘机制”,越老的记忆,越不信任。这在一定程度上缓解了滞后问题,让滤波器对变化更敏感了一些。
但从根本上,平均滤波的哲学是:在一个有限的窗口内,我相信真实信号是不变的。 这个假设,在快速变化的物理世界里,往往不堪一击。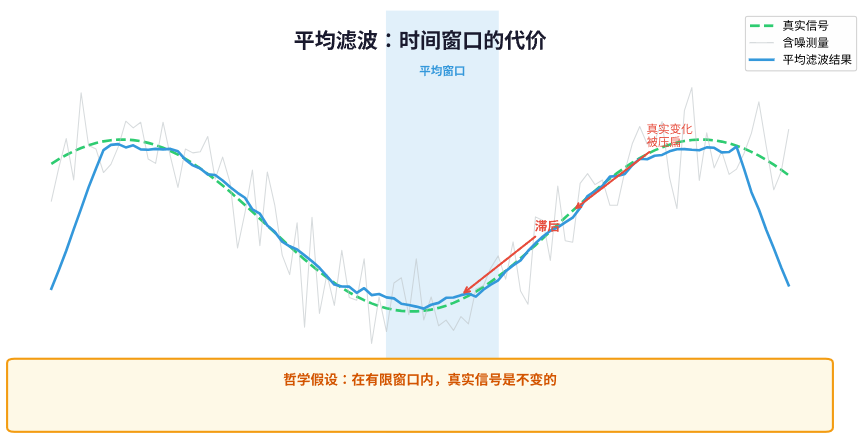
低通滤波
低通滤波是我个人觉得最优雅的入门滤波器之一。它的离散形式公式极其简洁:本次预测值 = a × 上次预测值 + (1-a) × 本次测量值
这个公式里藏着很多层理解。
从时间的角度看,它就是对“新”和“旧”的信任分配。a 越接近 1,你越相信历史,信号就越平滑,但响应也越迟钝。a 越小,你越相信当下的测量,响应快了,但噪声也进来了。
从频域的角度看,它叫“低通”是有原因的:它允许变化缓慢的低频信号通过,而阻隔变化剧烈的高频噪声。为什么?因为低频信号变化慢,前后两次采样的值差不多,你倾向于相信历史值,其实就是对信号本身没有造成太大扭曲。而高频噪声来了,你同样用巨大的惯性压住它,它就通不过。
但从信号响应的角度,这种“惯性”也就带来了相位延迟。因为你是通过滞后来平滑的,所以哪怕是一个真实的阶跃变化,低通滤波也会把它变成一个缓慢爬升的斜坡。它不会区分“好的突变”和“坏的毛刺”,一视同仁地打压。
所以低通滤波的哲学可以总结为:信号的变化频率是有限的,凡是快过某个限度的,都是噪声。 这个假设在很多场景下成立,但一旦你要追踪的目标本身就在做快速机动,它就抓瞎了。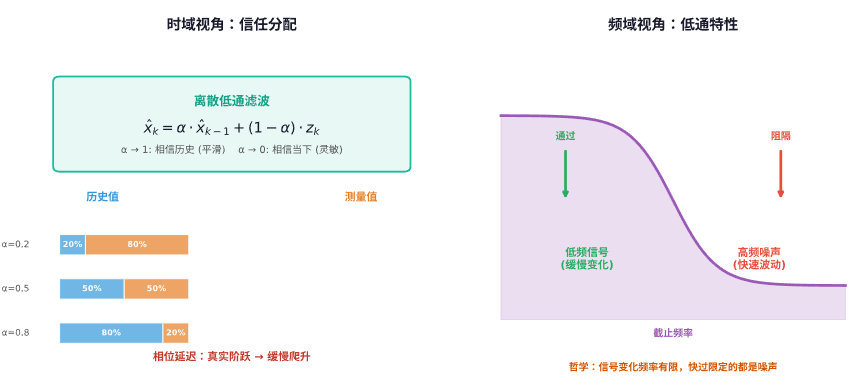
融合滤波
这个部分我觉得是思维从一维走向多维的关键一步。
在真实物理世界里,一个物理量往往不是只能通过一种手段去测量的。比如移动距离,你既可以用轮式编码器去算,也可以通过超声波或激光雷达去测。这两种测量的噪声特性完全不同——编码器怕打滑,超声波怕多径反射。
这里就出现了一个重要的哲学转折:与其在单一数据源的时间轴上费尽心思,不如引入多个数据源的横向轴。每个传感器看到的都是同一个真实值,但被不同的噪声污染了。如果你能把它们融合起来,互相印证,就有可能逼近真实。
最经典的例子是惯性导航里的 IMU 和 GPS 融合。IMU 对短时间内的微小动作极其敏感,响应快,但积分误差会随时间累积,长期来看完全不可信。GPS 恰好相反,短期有噪声,甚至可能丢信号,但长期它给出的是一个绝对无漂移的参考。
这两者形成了完美的互补。融合滤波在这里做的,不是一个固定权重的加权,而是动态地、自适应地去选择“在当下,我更应该相信谁”。短期信 IMU,长期信 GPS,而中间的所有状态,都是两者按某种最优方式组合出来的。
从设计哲学上讲,融合滤波不再把噪声当成一个需要被动忍受的东西,而是主动引入另一种信息维度来对抗它。你不再是一根筋地在一个传感器信号上做平滑,而是站在更高的维度上做“交叉印证”。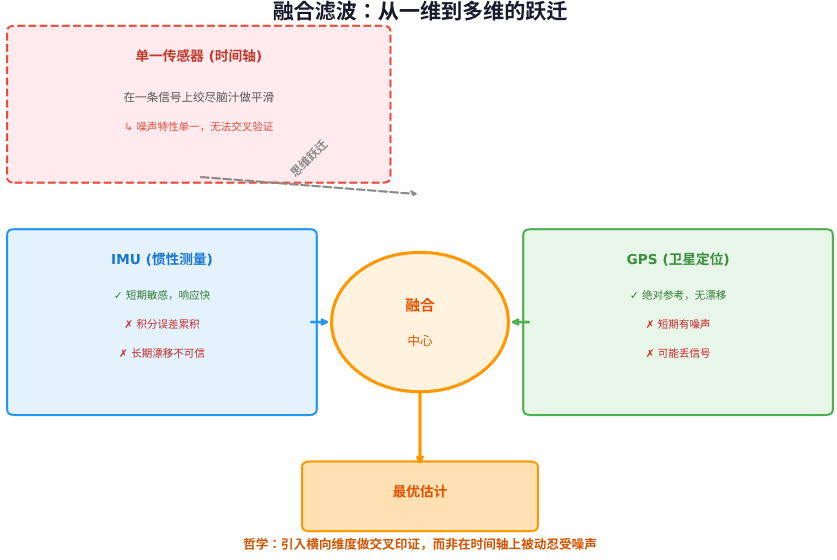
卡尔曼滤波
如果说前面的滤波都是技巧,那卡尔曼滤波就是理论。它把我前面所有讲到的权衡,都量化和统一在了一个框架里。
还是以融合滤波里提到的移动距离作为例子。我们有两种测量来源:编码器和超声波,这两种数据源都能测量同一个物理量,但是各自代表的意义是存在差异的。
编码器算出的移动距离,是基于轮速和时间的积分得到的。它不依赖外部参照物,完全是根据上一次的移动距离、这段时间的平均速度、以及过程中的噪声推算出来的。这种基于历史状态变化来进行预测的方式,对应的就是状态方程。
超声波算出的移动距离则不同。它是通过发射声波、接收回波来感知外部障碍物,从而反算距离的。这是一个从外部世界“观测”回来的值。我们拿到的观测值,等于那个我们永远不知道的真实距离,再加上超声波本身的多径误差、精度误差等观测噪声。这个关系,对应的就是观测方程。
更一般地来说:
状态方程描述的是“系统内部规律如何推动状态变化”。它的形式是:
当前状态 = 状态转移矩阵 × 上一时刻状态 + 控制输入 + 过程噪声
这里的过程噪声,代表的就是你对模型的不信任——你明白编码器的轮速模型不完美,会有阻力、会有打滑,所以你主动在方程里留了一个口子,承认这个预测是带着不确定性的。
观测方程描述的是“传感器如何从外部看到状态”。它的形式是:
观测值 = 观测矩阵 × 真实状态 + 观测噪声
这里的观测噪声,代表传感器的不可靠度。超声波测距时,障碍物表面不平、多径反射,都会引入误差。
这两个方程,一个根据系统模型遵循的物理规律去推结果,一个直接对物理世界进行测量去看结果,各说各的话,而且都不全对。卡尔曼滤波所做的,就是把这两个都不完美的信息源,按照各自的不确定性,融合成一个最优的估计。
卡尔曼滤波的运行,就是在这两个方程之间不断循环。先靠状态方程做一次预测,这代表着相信物理规律的部分;然后拿到传感器观测值,做一次更新,这代表相信传感器测量那部分。
而把这两者结合起来的,就是卡尔曼增益 K。这个增益不是人为调死的,而是每一时刻自动计算出来的。它考虑了两个不确定性:
预测的不确定性有多大?由状态协方差 P 和过程噪声协方差 Q 描述。
测量的不确定性有多大?由观测噪声协方差 R 描述。
Q 和 R 的比值,代表了你更信任系统模型还是观察传感器,本质上就是你最初那个“平滑 vs 细节”的比例。Q 设大一点,你就告诉滤波器:“模型不太靠谱,多信测量”,这样它就会保留快速变化,但也会引入一些噪声。R 设大一点,就是“传感器很烂,多信模型”,信号会变得平滑,但也可能丢失细节。
卡尔曼滤波最厉害的地方在于,它不需要你手动去折衷,而是每一时刻都通过协方差的传播,动态地计算出最优的信任分配。这是一种数据驱动的、带不确定性感知的自适应机制。
从数学哲学上看,协方差矩阵的传递,是一种信息的代谢。每一步预测,P 都会因为加入 Q 而变大,这代表了系统熵增,不确定性上升;每一步更新,P 都会被压缩,这代表从外部获得了信息,熵减。通过这种熵增熵减的循环,来保持最优估计。
而且,从几何意义上说,卡尔曼增益是在做正交投影。它找到的点,是预测向量和测量向量张成的空间里,离真实状态最近的那个点。这意味着,所有能从测量中提取出的有效信息,都被提取完了,残差里除了白噪声,再无任何剩余。这是一种极致的“无冗余”最优。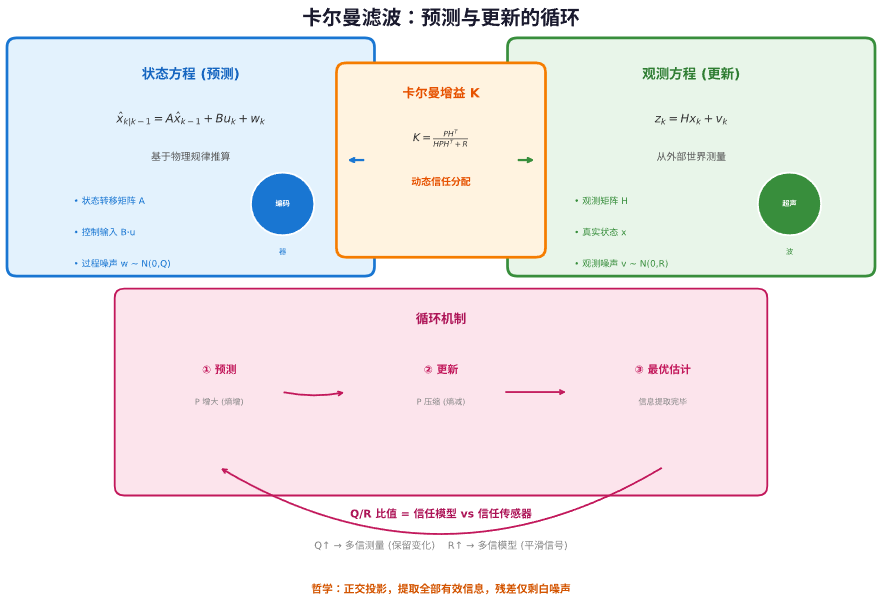
扩展卡尔曼与无迹卡尔曼
标准卡尔曼滤波有个要命的假设:系统得是线性。但现实世界,大部分系统都是非线性的,因此又提出了扩展卡尔曼与无迹卡尔曼两种改进方式。
扩展卡尔曼(EKF)的思路很直接:系统不是非线性的吗?那我就把它线性化。它在每个当前估计点上,对非线性函数做一阶泰勒展开,用切线去近似曲线。这就把非线性问题强行拉回了标准卡尔曼的框架。
EKF 的优点是小巧快,在工程上用了很多年。但它的问题是,一旦非线性程度很强,或者初始猜测太离谱,这条切线就歪了,滤波器可能会发散。而且求雅可比矩阵,有时候又麻烦又容易出错。
无迹卡尔曼(UKF)则换了一套完全不同的哲学:与其去近似函数,不如去近似分布。
它不碰那个非线性函数,而是根据当前状态的均值和协方差,精心选择一组西格玛点(样本点),让这些点穿过真实的非线性函数,然后把出来的结果重新拼成一个新的高斯分布。
这个做法抛弃了对函数的线性化,也就避免了计算雅可比矩阵。同时,它至少能捕捉到二阶矩信息,精度比 EKF 的一阶近似高出一个级别。在强非线性场景下,UKF 往往更稳定,更准确。
如果用个比喻:
EKF 就像一个工匠,想把一条弯弯曲曲的河每一段都画成直线,靠得很近看,好像也对。
UKF 则派出一队侦察兵,让他们亲自走过这片复杂的地形,回来之后告诉你整个区域的真实情况。
从设计哲学上来说,UKF 更接近贝叶斯估计的原意:我们不是在操纵一条条方程,而是在传播一整个概率分布。卡尔曼滤波本身,就是一种对高斯分布传播的优雅实现,而 UKF 把这种优雅带到了非线性世界。